Initial Experiment Using Claude Code for RL Research
This week I spent some time exploring how the current generation of coding models (I used Claude Opus 4.6 and GPT 5.4 xhigh) can be used to automatically carry out ML research. All of the code was written by the models and is available on GitHub. During my undergrad and first year of my PhD I focused my research on multi-agent RL in zero-sum games, so as a basic test, I gave the following prompt to both Opus 4.6 in Claude Code and GPT 5.4 xhigh in the Codex app1:
Codex (GPT 5.4 xhigh) ran for 25 minutes and solved tic-tac-toe optimally using a tabular policy with a 3-phase hyperparameter sweep. It tended toward game-specific shortcuts: symmetry encodings, and once it even distilled the minimax-optimal policy directly instead of getting the RL to work. The report it generated was not readable.
Claude Code (Opus 4.6) ran for around an hour and approached the problem more similarly to how I would have done it. It implemented a small MLP policy in PyTorch and ran a hyperparameter sweep over learning rate, entropy bonus, network size, opponent sampling, batch size, PPO clip epsilon, and snapshot interval ( report). The final tuned agent achieved 90% win rate vs random and 0% exploitability (100% draw rate vs minimax):
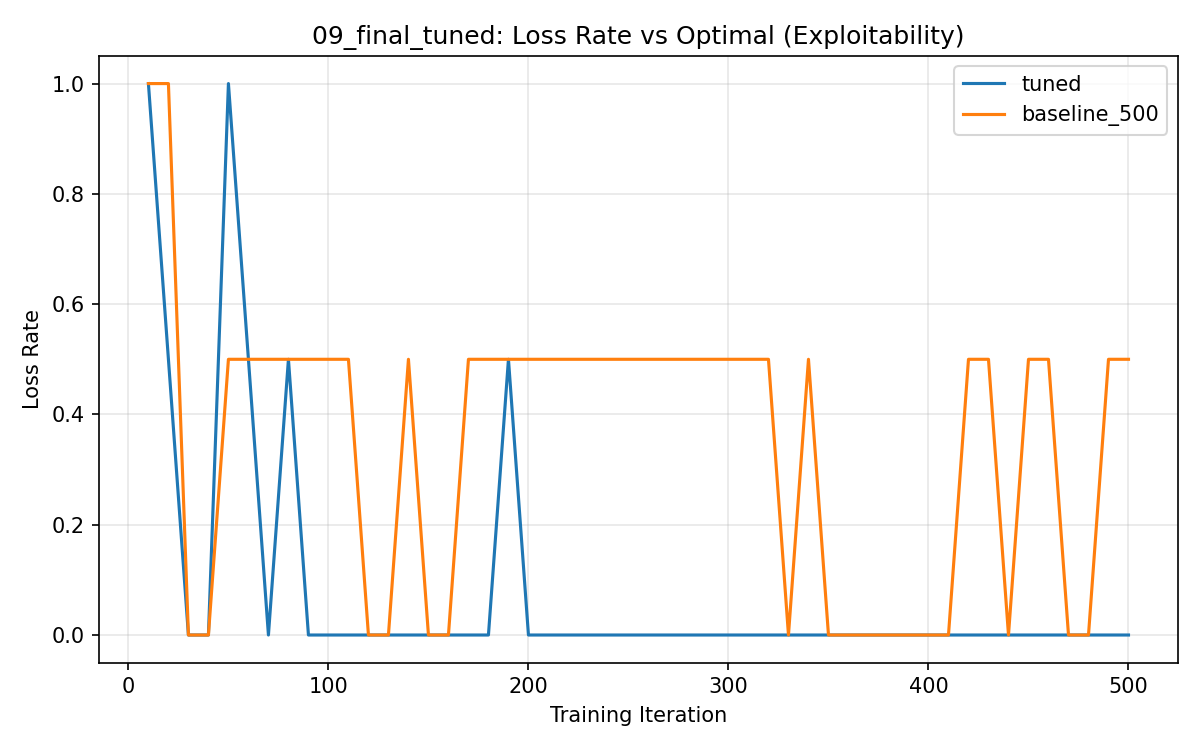
My main criticisms: the training curves are very noisy (no multiple seeds), the hyperparameters are not independent (learning rate, batch size, and architecture interact in predictable ways), and Opus tends to rationalize every result even when the data is inconclusive.
Performance Optimization
Next, I tasked Opus with optimizing the training speed:
Opus profiled the code ( report), identified that game collection was 61% of the runtime, and vectorized the environment (running all 512 games in parallel with NumPy) and batched the neural network forward passes (~4,600 individual calls down to ~9). This gave a 28x speedup on the collection phase and 2.57x overall:
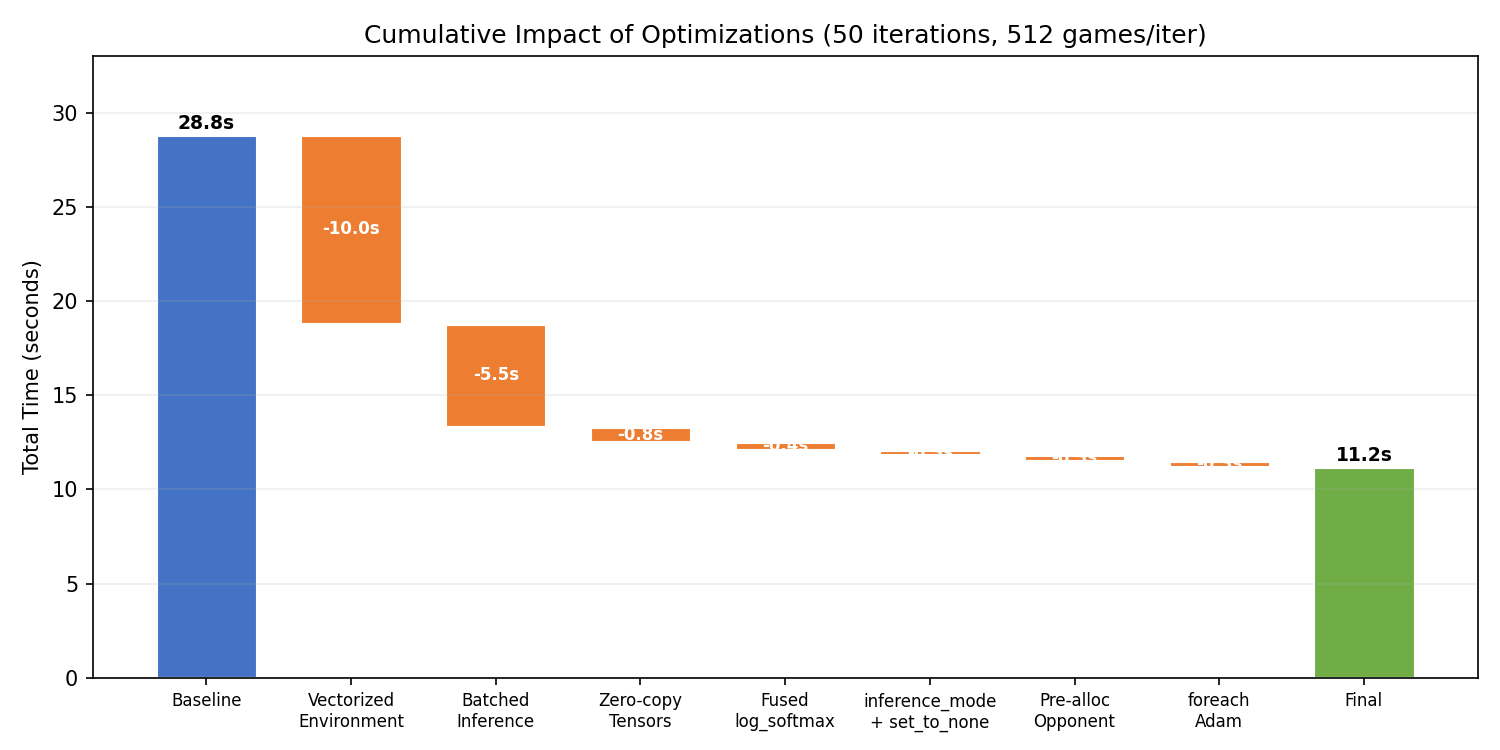
These optimizations probably should have been standard from the start. I would have hoped Opus would implement vectorized environments and batched inference before running a hyperparameter sweep. It’s likely that today’s models don’t have a strong sense of time.
I then pushed it further:
Opus rewrote the entire training pipeline in C with hand-written forward/backward passes using Apple’s Accelerate BLAS, optimized for the M2 Max in my Macbook Pro ( report). It reasoned about the theoretical compute and memory bandwidth limits of the hardware and ended up at 37ms per update, which it says is 2.8x from the theoretical floor. This gave a further 14.9x speedup over the optimized PyTorch code:
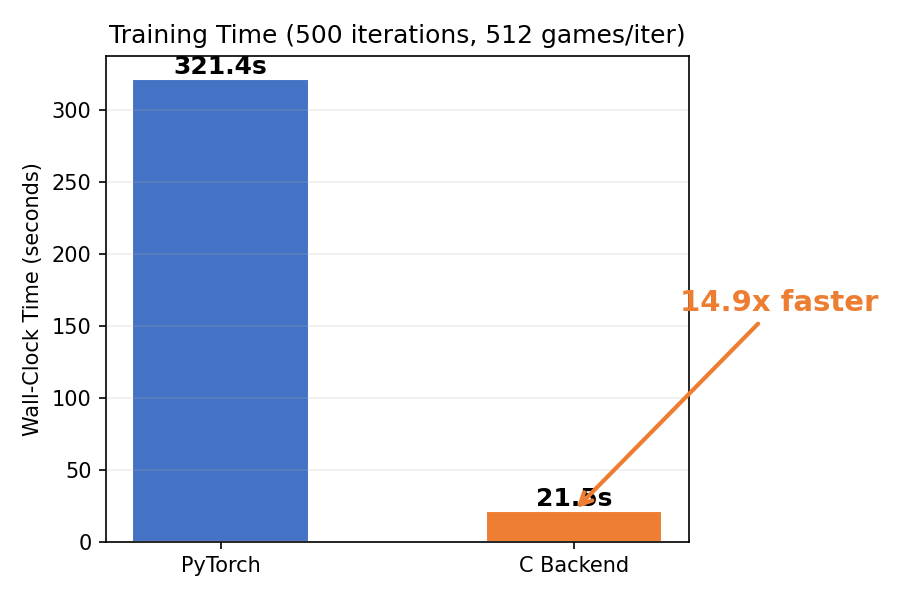
The C version initially didn’t learn at all. Opus noticed this, investigated, and found three bugs: an observation encoding layout mismatch, a GAE transition ordering issue from vectorized collection, and a -ffast-math catastrophic cancellation bug where the compiler reordered lg[j] + (1.0f - vm[j]) * (-1e8f) into (lg[j] - 1e8f) + vm[j] * 1e8f, zeroing out every logit due to float32 precision limits. After fixing all three, the C backend converged to optimal play within 25 iterations.
Connect Four and Open-Ended Research
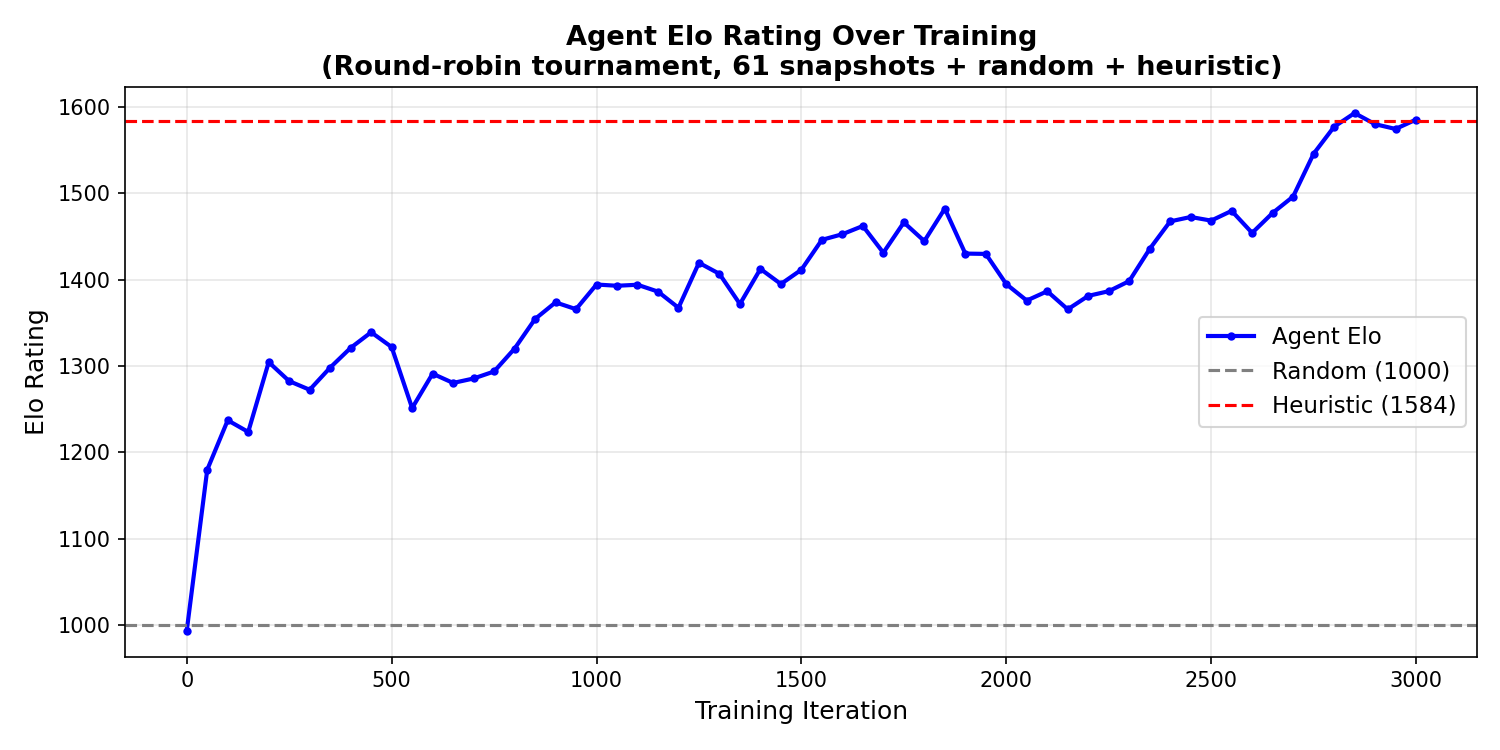
I moved to Connect Four to increase the complexity. Initial results were weak ( report): Opus declared success despite poor performance against a simple heuristic opponent. After I suggested implementing Elo as a more stable metric, this is what the initial Elo curve looked like:
I then gave Opus an open-ended prompt to optimize it:
Opus ran for 18 hours until I told it to wrap up ( report). It ran 18 experiments with ~40 total runs, increasing the Elo from 1600 to a peak of 1970 but falling short of the 2100 target. The biggest wins were increasing games per iteration from 512 to 2048 (+181 Elo) and adding opponent temperature of 1.5 (+84 Elo). Many other ideas like mirror augmentation, conservative clipping, entropy schedules, either hurt or had no effect.
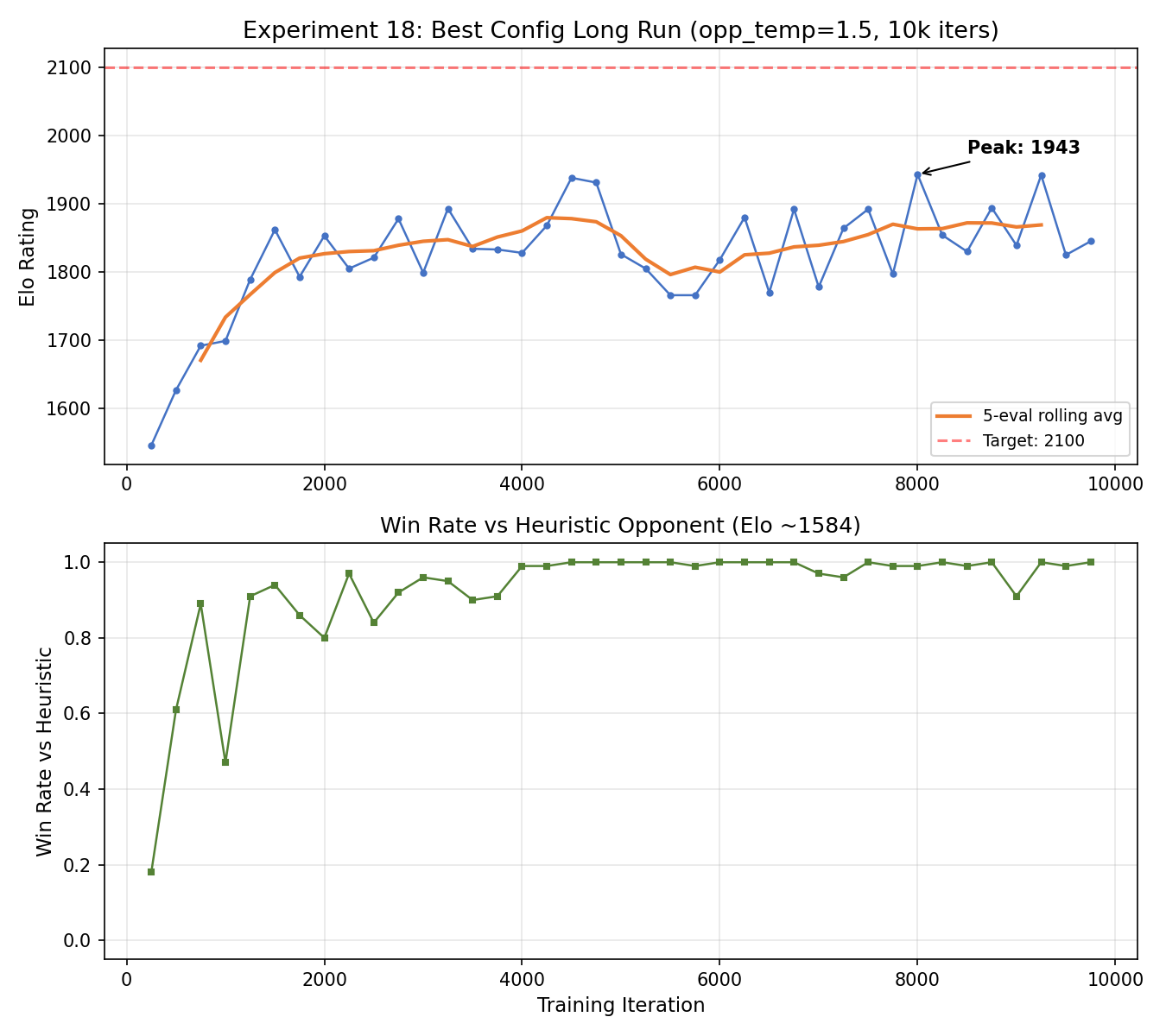
My main criticisms: it optimized peak Elo rather than a smoothed metric, most experiments were brute-force sweeps of simple hyperparameters rather than deeper investigations, and it didn’t analyze why the agent was losing to specific opponents.
Takeaways
- When the task is easily-evaluatable, such as performance optimization, Opus is already good enough. In the C implementation, it correctly identified that training wasn’t reaching expected performance, designed a test, and dug into the code to find all three bugs - something that surprised me a bit.
- The model has surprisingly bad behavior in some important areas, such as evaluation and hyperparameter tuning. It uses single seeds, reports noisy metrics, and often tries an idea once and moves on without understanding why it failed. I also caught it writing scripts that run training, plot results, and generate the report all in one go, meaning it wrote commentary on results it hadn’t looked at.
- Research taste is still pretty off. Opus doesn’t have a strong simplicity bias and sometimes tries overly task-specific solutions. Codex is worse for that. It also chose outdated defaults (plain ReLU MLP) that immediately improved when I suggested layernorm, residual connections, and GELU. This is something that I think could be improved through some high quality human data.
-
The prompts are all super informal and not well thought out. That’s just how I interact with Claude Code! ↩